01 vLLM 快速部署入门
参考文献
- Se7en. AI Infra
- 教程:vLLM Quickstart.
- 原文链接:https://cr7258.github.io/courses/ai-infra/AI%20Infra%20教程/01-vllm-quickstart
版权:CC BY-SA 4.0(署名—相同方式共享)
1 什么是 vLLM?
vLLM 是一个高效、易用的大语言模型(LLM)推理和服务框架,专注于优化推理速度和吞吐量,尤其适合高并发的生产环境。它由加州大学伯克利分校的研究团队开发,并因其出色的性能成为当前最受欢迎的 LLM 推理引擎之一。

vLLM 同时支持在 GPU 和 CPU 上运行,本文将会分别介绍 vLLM 使用 GPU 和 CPU 作为后端时的安装与运行方法。
2 前提准备
2.1 购买虚拟机
如果本地不具备 GPU 环境,可考虑通过云服务提供商(如阿里云、腾讯云等)购买 GPU 服务器。
操作系统建议选择 Ubuntu 22.04,GPU 型号可根据实际需求进行选择。由于大语言模型通常占用较多磁盘空间,建议适当增加磁盘容量。

2.2 虚拟环境
推荐使用 uv 来管理 python 虚拟环境,执行以下命令安装 uv:
curl -LsSf https://astral.sh/uv/install.sh | sh
source $HOME/.local/bin/env
# or uv 也可以 pip 装(虽然官方推荐使用二进制)国内源比较快
pip install uv --index-url https://pypi.tuna.tsinghua.edu.cn/simple
# Installing collected packages: uv
# Successfully installed uv-0.9.11
3 安装
3.1 使用 GPU 作为 vLLM 后端
3.1.1 系统要求
vLLM 包含预编译的 C++ 和 CUDA (12.6) 二进制文件,需满足以下条件:
- 操作系统:Linux
- Python 版本:3.9 ~ 3.12
- GPU:计算能力 7.0 或更高(如 V100、T4、RTX20xx、A10、A100、L4、H100 等)
注:计算能力(Compute capability)定义了每个 NVIDIA GPU 架构的硬件特性和支持的指令。计算能力决定你是否可以使用某些 CUDA 或 Tensor 核心功能(如 Unified Memory、Tensor Core、动态并行等),并不直接代表 GPU 的计算性能。
3.1.2 安装和配置 GPU 依赖
可以使用以下命令一键安装相关依赖,该脚本会安装 NVIDIA GPU Driver,NVIDIA Container Toolkit,以及配置 NVIDIA Container Runtime(后续通过 Docker 运行 vLLM 时需要)。
curl -sS https://raw.githubusercontent.com/cr7258/hands-on-lab/refs/heads/main/ai/gpu/setup/docker-only-install.sh | bash
3.1.3 安装 vLLM
创建 Python 虚拟环境
# (Recommended) Create a new uv environment. Use `--seed` to install `pip` and `setuptools` in the environment.
uv venv --python 3.12 --seed
source .venv/bin/activate
# output
# Using CPython 3.12.3 interpreter at: miniconda3/bin/python3.12
# Creating virtual environment with seed packages at: .venv
安装 vLLM
uv pip install vllm
# or 国内镜像源
uv pip install vllm -i https://pypi.tuna.tsinghua.edu.cn/simple
# 验证
python3 -c "import vllm; print(vllm.__version__)"
# 0.11.2
4 离线推理 vs 在线推理
离线推理(offline inference)和在线推理(online inference)的主要区别在于使用场景、延迟要求、资源调度方式等方面,简单总结如下。
4.1 离线推理
对一批输入数据进行集中处理,通常不要求实时返回结果。特点如下
- 批处理:常用于处理大量输入,如日志分析、推荐系统预计算。
- 低延迟要求:结果可以晚些返回,不影响用户体验。
- 资源利用高:系统可以在空闲时充分利用 GPU/CPU 资源。
- 示例场景:每天夜间跑用户兴趣画像、预生成广告文案等。
4.2 在线推理
针对用户实时请求进行推理,立即返回结果。特点如下
- 实时响应:响应时间通常要求在几百毫秒以内。
- 延迟敏感:高�并发、低延迟是核心指标。
- 资源分配稳定:服务需长时间在线、资源预留固定。
- 示例场景:聊天机器人、搜索联想、智能客服等。
5 离线推理
安装好 vLLM 后,你可以开始对一系列输入提示词进行文本生成(即离线批量推理)。以下代码是 vLLM 官网提供的示例:
# basic.py
# https://github.com/vllm-project/vllm/blob/main/examples/offline_inference/basic/basic.py
from vllm import LLM, SamplingParams
# Sample prompts.
prompts = [
"Hello, my name is",
"The president of the United States is",
"The capital of France is",
"The future of AI is",
]
sampling_params = SamplingParams(temperature=0.8, top_p=0.95)
def main():
# 使用 Qwen/Qwen2.5-1.5B-Instruct
# Qwen/Qwen2.5-0.5B-Instruct
llm = LLM(
model="Qwen/Qwen2.5-0.5B-Instruct",
gpu_memory_utilization=0.75,)
outputs = llm.generate(prompts, sampling_params)
print("\nGenerated Outputs:\n" + "-" * 60)
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
print(f"Prompt: {prompt!r}")
print(f"Output: {generated_text!r}")
print("-" * 60)
if __name__ == "__main__":
main()
在上面的代码中,使用了 SamplingParams 来指定采样过程的参数。采样温度设置为 0.8,核采样概率设置为 0.95。下面解释一下这两个参数的用途:
Sampling Temperature(采样温度) 和 Nucleus Sampling Probability(核采样概率/Top-p) 是大语言模型生成文本时常用的两个采样参数,用于控制输出文本的多样性和质量。
- 采样温度(Sampling Temperature)
- 作用:控制生成文本的“随机性”或“创造性”。
- 原理:温度会对模型输出的概率分布进行缩放。温度越低(如 0.5),高概率的词更容易被选中,生成结果更确定、重复性更高;温度越高(如 1.2),低概率的词被选中的机�会增加,文本更有多样性但可能更混乱。
- 具体来说,temperature=0.8 表示在概率分布上做了一定程度的“平滑”,比默认的 1.0 更偏向于选择高概率词,但仍保留一定的多样性。
- 核采样概率(Nucleus Sampling Probability / Top-p)
- 作用:控制每一步生成时考虑的候选词集合大小,动态平衡文本的多样性和合理性。
- 原理:Top-p(核采样)会将所有词按概率从高到低排序,累加概率,直到总和首次超过 0.95 为止,只在这部分“核心”词中随机采样。
这里用一个例子来解释这两个采样参数之间的关系,假设模型下一步可以说 “猫 狗 老虎 大象 猴子 乌龟 老鹰 鳄鱼 蚂蚁 ...”(有上万个词):
Temperature是调整每个词出现的概率(“猫”的概率是 30%,你可以把它调得更大或更小);Top-p是把所有词排序后,只保留累计概率达到 95% 的前几个词,比如前 7 个,然后从中挑一个。
输出是通过 llm.generate 方法生成的。该方法会将输入提示加入 vLLM 引擎的等待队列,并调用 vLLM 引擎以高吞吐量生成输出。最终输出会以 RequestOutput 对象列表的形式返回,每个对象包含完整的输出 token。
执行以下代码运行程序:
mkdir -p llm && vim llm/01basic.py
cd llm
python 01basic.py
# Debug1 会报错连接不上 HuggingFace,可以设置环境变量
export HF_ENDPOINT=https://hf-mirror.com
# 验证
curl -I https://hf-mirror.com/
# 如果能返回 200 → 就可以下载模型了。
# 再次运行
python 01basic.py
# 清空文件内容并重新复制代码
: > 01basic.py
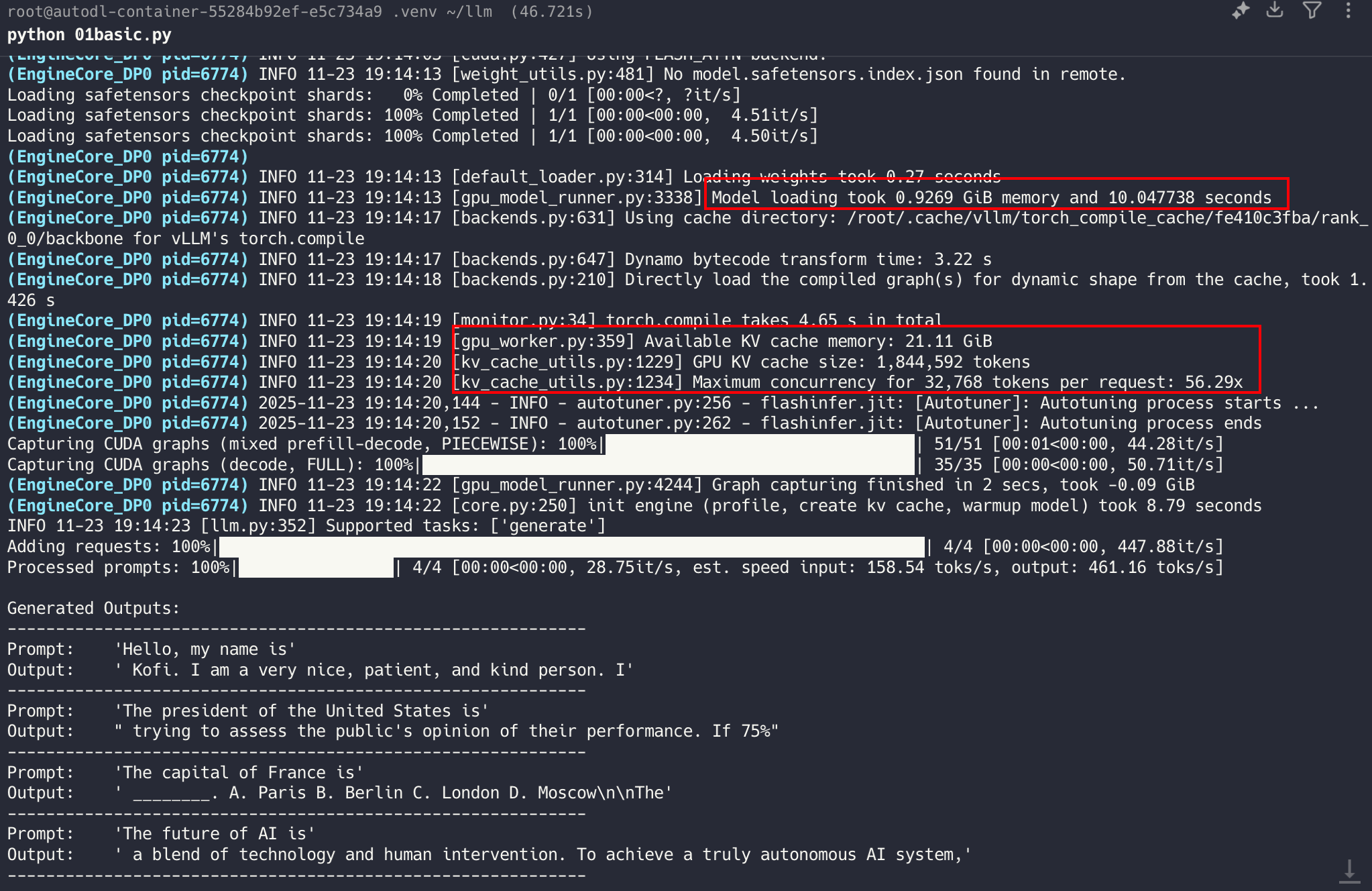
Debug 常见问题
# Debug2 你这块显卡总共 31.36 GiB,启动时只有 27.09 GiB 空闲,
# 但 vLLM 想按 gpu_memory_utilization=0.9 预留 28.22 GiB,所以它觉得空闲显存不够,直接报错退出了。
nvidia-smi
# GPU: RTX 5090
# 总显存: 约 32 GB
# 当前占用: 3.7 GB
# 空闲显存: 约 28.3 GB
# 手动释放显存
sudo kill -9 <PID> # 杀掉占 GPU 的进程
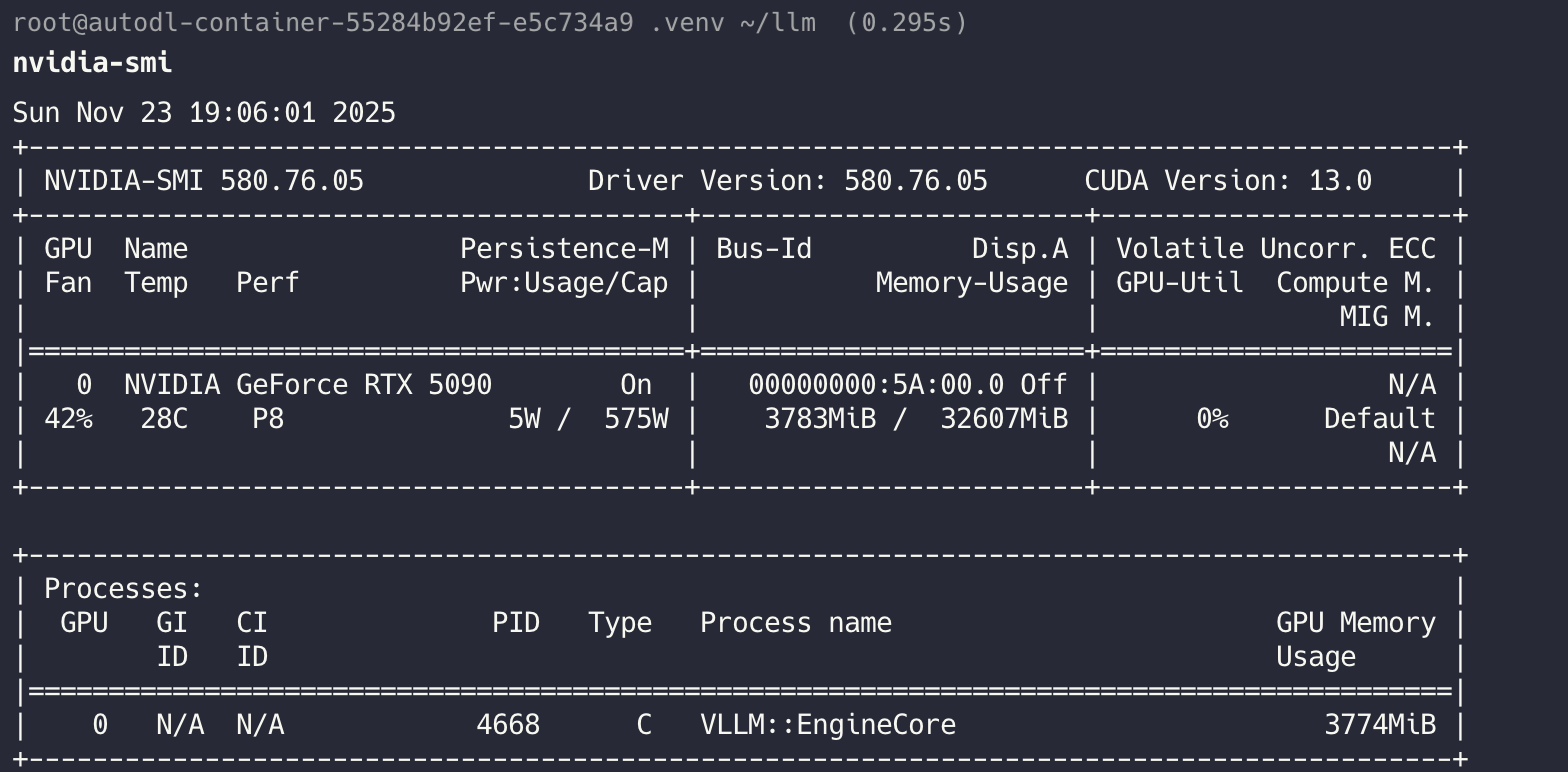
6 在线推理
vLLM 可以部署为实现 OpenAI API 协议的服务器。默认情况下,服务器在 http://localhost:8000 启动。你可以通过 --host 和 --port 参数指定地址。服务器目前一次只能托管一个模型,实现了 list models,create chat completion 等端点。
运行以下命令以启动 vLLM 服务器,并使用 Qwen/Qwen2.5-1.5B-Instruct 模型:
vllm serve Qwen/Qwen2.5-1.5B-Instruct
启动后的输出如下
这个服务器可以像 OpenAI API 一样以相同的格式进行请求。例如,要列出模型
curl -sS http://localhost:8000/v1/models | jq
# Debug3 如果没有安装 jq,可以直接运行下面的命令
sudo apt update
sudo apt install -y jq
# output
{
"object": "list",
"data": [
{
"id": "Qwen/Qwen2.5-1.5B-Instruct",
"object": "model",
"created": 1763896843,
"owned_by": "vllm",
"root": "Qwen/Qwen2.5-1.5B-Instruct",
"parent": null,
"max_model_len": 32768,
"permission": [
{
"id": "modelperm-3d933d4ac16042f5966ecd690be3b5da",
"object": "model_permission",
"created": 1763896843,
"allow_create_engine": false,
"allow_sampling": true,
"allow_logprobs": true,
"allow_search_indices": false,
"allow_view": true,
"allow_fine_tuning": false,
"organization": "*",
"group": null,
"is_blocking": false
}
]
}
]
}
6.1 使用 vLLM 的 OpenAI Completions API
你可以使用输入提示词查询模型
curl -sS http://localhost:8000/v1/completions \
-H "Content-Type: application/json" \
-d '{
"model": "Qwen/Qwen2.5-1.5B-Instruct",
"prompt": "北京是一个"
}' | jq
# output
{
"id": "cmpl-c1c6332d810243f3a10227c1dac38cb6",
"object": "text_completion",
"created": 1763896879,
"model": "Qwen/Qwen2.5-1.5B-Instruct",
"choices": [
{
"index": 0,
"text": "历史悠久的城市,有许多历史遗迹和文化景点。以下是一些值得一看的",
"logprobs": null,
"finish_reason": "length",
"stop_reason": null,
"token_ids": null,
"prompt_logprobs": null,
"prompt_token_ids": null
}
],
"service_tier": null,
"system_fingerprint": null,
"usage": {
"prompt_tokens": 2,
"total_tokens": 18,
"completion_tokens": 16,
"prompt_tokens_details": null
},
"kv_transfer_params": null
}
7 vLLM GPU 性能测试
当前进行测试的 GPU 服务器配置参数如下
- GPU: NVIDIA GeForce RTX 5090
- 显存: 大约 32 GB(Memory-Usage: xxxx MiB / 32607 MiB)
- 驱动版本: Driver Version: 580.76.05
- CUDA 版本: CUDA Version: 13.0
以下是一个简单的单机压测脚本 顺序 100 次请求
#!/usr/bin/env bash
set -euo pipefail
########################################
# 配置区:根据需要修改
########################################
# vLLM 服务地址
URL="http://localhost:8000/v1/chat/completions"
# 模型名称(和 vLLM 启动时一致)
MODEL="Qwen/Qwen2.5-1.5B-Instruct"
# 压测请求内容
PROMPT="Tell me a joke"
# 默认请求次数,可在命令行传参数覆盖,比如:./bench_vllm.sh 200
N=${1:-100}
########################################
# 压�测开始
########################################
# 临时文件用于存放每次请求的延迟(毫秒)
tmp_file=$(mktemp)
echo "====== vLLM 单机压测 ======"
echo "目标 URL : $URL"
echo "模型 : $MODEL"
echo "请求内容 : $PROMPT"
echo "请求总数 : $N 次"
echo
# 记录整体开始时间(毫秒)
start_all=$(date +%s%3N)
for ((i=1;i<=N;i++)); do
t0=$(date +%s%3N)
# 发送请求(丢弃响应体,只测性能)
curl -sS "$URL" \
-H "Content-Type: application/json" \
-d "{
\"model\": \"$MODEL\",
\"messages\": [
{\"role\": \"user\", \"content\": \"$PROMPT\"}
]
}" > /dev/null
t1=$(date +%s%3N)
latency=$((t1 - t0)) # 单次请求耗时(毫秒)
echo "$latency" >> "$tmp_file"
echo "请求 $i 延迟: ${latency} ms"
done
end_all=$(date +%s%3N)
total_ms=$((end_all - start_all))
echo
echo "==== 性能统计 ===="
awk -v total_ms="$total_ms" '
{
s+=$1; a[NR]=$1
}
END{
n=NR
if (n == 0) {
print "没有采集到任何延迟数据"
exit 1
}
# 需要 gawk 支持 asort
asort(a)
avg = s/n
p50 = a[int(0.5*n)]
p95 = a[int(0.95*n)]
max = a[n]
printf "请求总数 : %d 次\n", n
printf "总耗时 : %.2f 秒\n", total_ms/1000
printf "吞吐量(QPS) : %.2f 请求/秒\n", n/(total_ms/1000)
printf "延迟(毫秒)\n"
printf " 平均延迟 : %.2f ms\n", avg
printf " P50 延迟 : %.2f ms\n", p50
printf " P95 延迟 : %.2f ms\n", p95
printf " 最大延迟 : %.2f ms\n", max
}' "$tmp_file"
# 清理临时文件
rm -f "$tmp_file"
# 安装必备依赖
# Ubuntu 镜像里默认是 mawk
# 不是 gawk,所以没有 asort 函数(asort 只有 GNU awk 才支持)
sudo apt update
sudo apt install -y gawk
vim single_bench.sh
chmod +x single_bench.sh
# 运行压测
./single_bench.sh
# output
====== vLLM 单机压测 ======
==== 性能统计 ====
请求总数 : 100 次
总耗时 : 13.10 秒
吞吐量(QPS) : 7.63 请求/秒
延迟(毫秒)
平均延迟 : 128.67 ms
P50 延迟 : 118.00 ms
P95 延迟 : 192.00 ms
最大延迟 : 389.00 ms