17. Design Recommender System
01 背景需求
互联网的一个主要应用就是信息匹配,只有与人发生关系的信息才具有价值,因此人与信息的匹配是互联网应用的核心问题。信息匹配的方式有多种:
- 门户
- 订阅
- 搜索
- 推荐
早期互联网用户以内门户展示信息为主,类似专栏陈列的商品;由网站维护人员更新信息,所有人看到的信息都一样。代表就是搜狐/网易/新浪,互联网的技术发展主要推动因素就是计算广告的技术发展,为了提供更大量的广告信息,让网站能够展示更多的信息,因此由于订阅模式或者 SRR/社区等停止,转向了社交关系后,预测感兴趣的内容主要代表就是新浪微博、天涯社区等等。
但有很多信息并不能通过社交关系获得因此出现了搜索需求,用户通过一些 query 来查询到自己想要的信息,这还是信息找人的时代,主要代表就是谷歌/百度/搜狗。再后来,随着互联网上的信息越来越多,人们陷入了选择困境,人们在阅读信息之前,可能对信息一无所知,只有看到时才知道是否喜欢,人们越来越懒,这就催生出了 推荐系统: 基于用户广泛的历史行为,预测用户可能感兴趣的信息主动推送,从而达到用户与信息的匹配。
由于用户在推荐之前并不知道内容是什么,扩大了信息的候选范围,进一步提高了潜在的广告位数量,这成为互联网应用的核心竞争力,这是技术与业务的完美结合。
02 约束条件
- 业务目标: 互联网技术本质上是为了用户需求服务的,推荐系统的目标就是增加留存、使用时长等。
- 低延迟: 推荐系统作为核心的在线系统,必须要求可能的降低延迟,因为每降低 20ms 就可以上线一个策略,来优化业务目标,同时刷新首页信息流的延迟感会直接影响用户体验。
- 稳定性: 推荐系统是跟业务目标直接相关的,如果出现问题会直接降低用户留存,使用时长等指标直接影响公司收入,因为通常广告业务需要依赖留存与使用时长进行变现。
- 迭代效率&质量: 必须做到足够快,推荐系统的迭代速度直接影响公司的竞争能力,同时要对复杂系统保持高迭代效率,势必会导致问题频发,如何保证推荐系统质量是一个能力的拉锯战。
- 成本: 推荐系统需要大量的存储/计算/网络成本,如向优化成本的机器资源成本,这将直接影响收入。
03 技术方案
如果你要给一个朋友推荐一本书你需要怎么做?
- 第一步. 你要自己读过很多书,这样朋友问你的时候才能及时地推荐给朋友。
- 第二步. 你应该尽可能的了解这个朋友(你对他的印象/他现在的状态/他想看什么书)。
- 第三步. 基于你对这个朋友的了解以及对你读过的书的了解,潜意识快速筛选出几十本可以推荐的书。
- 第四步. 然后快速的对这几十本书进行猜测,你这位朋友喜欢这几本书的概率有多大?��然后按概率排个序。
- 第五步. 取 top 结果推荐,基于朋友的反馈,你修正了对朋友兴趣的理解,你的猜测将变得更加准确。
- 第六步. 如果你觉得朋友适合看你刚写的书,那么你会在推荐中夹带私货,强调安利自己的书 (广告)。
- 第七步. 再次推荐书籍时可能会重复推荐,当你发现朋友曾看过你推荐过的书时,你要把他忽略。
这个信息匹配的本质就是推荐的基本原理。 将人的兴趣量化,再将要推荐的物品特征进行量化,将两个量化值进行计算得出一个分值,然后对所有的计算结果取 top-k,返回 top-k 的结果。这个过程就是推荐的基本原理。为了实现这一基本步骤,我们发明了多种推荐算法。
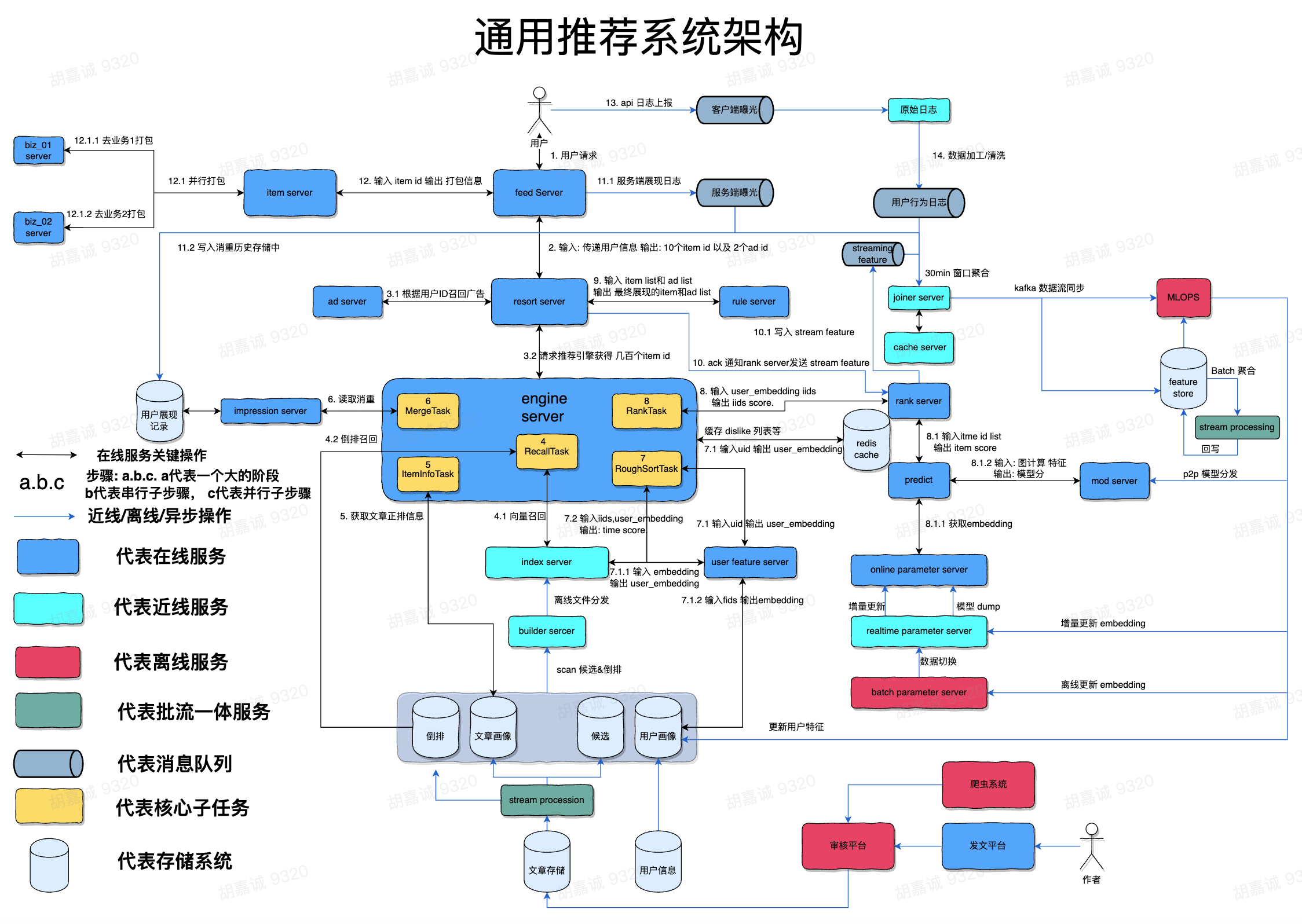
根据对推荐算法的分类以及基本原理的理解,我们可以对推荐系统按数据流的构建过程划分为多个模块
- 候选构建: 从全量内容中初步筛选出一批可能感兴趣的物品,作为后续推荐的候选池。
- 特征工程: 提取用户、物品及上下文的属性特征,为模型提供有信息量的输入。
- 召回系统: 利用协同过滤、Embedding 相似度等方法,从候选池中快速召回相关性较高的内容。
- 排序系统: 使用机器学习或深度学习模型对召回结果进行打分,排序输出最终推荐列表。
- 模型训练: 基于用户行为数据训练召回和排序模型,不断优化推荐效果。
- 混排系统: 将多个推荐来源(如广告、主站内容等)结果融合,统一排序,提升整体体验和收益。
- 消重系统: 去除重复内容或用户已看过的项目,保障推荐内容的新颖性和多样性。
3.1 基本概念
- item: 代表信息的容器,可以是一个视频/文章/商品/广告等等。
- 消费: 用户浏览 item 承载的信息,然后发生一系列行为,播放/点赞/收藏/关注/转发/购买/等等。
- 分发: 决定将哪些 item 与用户匹配,展示给用户进行消费的过程就是分发过程。
- 打包: 推荐系统决定分发哪些 item 给到用户,但是推荐系统不关注 item 承载哪些信息,它只关注 item 具有的特征,因此打包就是将用户能够浏览的信息拼接封装到 item 的这个容器中展示给用户的过程。
- user: 消费或者生产 item 的用户。
- 候选: 准备推荐给用户消费的 item 数据集合。
- 预估: 深度学习模型的前向传播。
- 召回: 信息检索的一个过程,通过一个 key 获得一堆相关的 id。
- 排序: 对召回的 id,按照某种分值进行排序。
- 数据流: 数据整个生命周期的处理过程。
- 特征: 物理上客观事物所蕴含信息的数学表达。
- 样本: 用于机器学习模型训练的数据特征。
3.2 候选构建
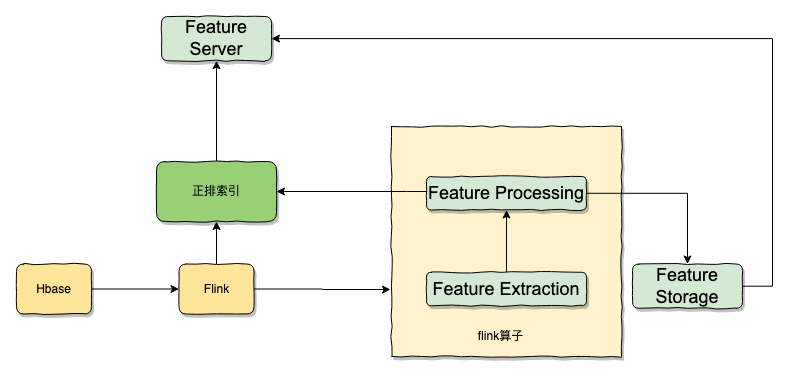
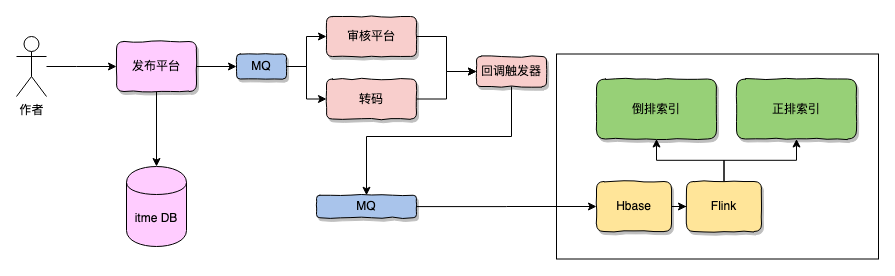
当文章/视频 (item)内容发布后,经过一些审核与处理后需要将 item 存储为易于推荐系统查询的格式,通常就是正排+倒排。 这两种数据结构覆盖了基本的查询需求,用来为推荐引擎的候选构建提供基础的数据支撑。
所以候选集合本质上就是一个易于推荐引擎查询数据的索引结构,是为推荐提供数据的模块。
正排 Forward Index 示例
- 正排就是以 itemID 为 key,然后一些 item 相关的结构化属性进行序列化后,存储好的 kv 数据项。
- 正排结构通常是
itemID -> item属性
// 假设你有一个视频内容平台,发布了一条视频,其 itemID = 12345
{
"itemID": 12345,
"title": "如何快速掌握推荐系统",
"tags": ["推荐系统", "机器学习", "算法"],
"category": "技术分享",
"author": "小明",
"publishTime": "2025-07-01T08:00:00Z"
}
倒排 Inverted Index 示例
- 倒排就是以某个属性或者计算的 tag 为 key,value 是一个 timeID 的 list
- 倒排结构通常是
属性值 -> 一组 itemIDs
场景:你有一个图书平台,用户感兴趣的标签(Tag)包括“科幻”“人工智能”“畅销书”。你系统中有若干本书,每本书都有一个唯一的 itemID,例如:
- 书 A(itemID: 10001):《��三体》 → 标签:科幻、畅销书
- 书 B(itemID: 10002):《人工智能简史》 → 标签:人工智能、畅销书
- 书 C(itemID: 10003):《银河帝国》 → 标签:科幻
- 书 D(itemID: 10004):《机器学习导论》 → 标签:人工智能
// 倒排索引长什么样?
{
"科幻": [10001, 10003],
"人工智能": [10002, 10004],
"畅销书": [10001, 10002]
}
倒排索引在广告系统中常用于快速定位可投放广告,本质是根据用户特征或曝光上下文,从广告属性倒排表中高效召回符合条件的广告集合。信息流广告的推荐过程本质上也依赖类似机制进行实时匹配与筛选。
| 场景 | 倒排索引作用 |
|---|---|
| 定向投放 | 根据用户属性(如性别、兴趣、地域等)构建倒排索引,如“兴趣:游戏” -> [广告 A, 广告 B],当用户访问时快速查找符合定向条件的广告集合 |
| 实时竞价 RTB | 用户到达页面后,根据其画像快速匹配一批符合条件的广告,如“高消费 + iOS + 体育” -> [广告 X, 广告 Y],进入竞价流程 |
| 屏蔽规则 | 构建“不可投人群”倒排索引,如“18 岁以下” -> [广告 P],用于排除特定广告,保障合规和体验 |
| 用户行为建模 | 记录用户点击、浏览等行为所涉及的标签,如点击“篮球鞋”广告 → 增强用户的“体育”兴趣标签,辅助后续兴趣建模和广告精准推荐 |
3.3 特征工程