24. Design Bullet Screen System 弹幕系统
本节将介绍弹幕系统的设计,包括其架构、关键组件以及实现细节。
aka Danmaku System
00 Resources
01 Background 背景
用户通过发送弹幕、送礼等,可以实时在直播画面上展现自己的想法、评论和互动内容,从而丰富了用户观看体验。可以类比的是:
- 一种 "群" 消息,将某个用户 (也有系统) 产生的消息实时广播给全体 "群成员"
- 这个群动辄数百万成员
- 这个群是临时的 (进了某个直播间,一会儿又退出了)
- 消息基于直播间,进直播间才能收到消息
- 这种群消息可分布在多端。APP、Web、H5
- 这种消息阅后即焚,因为和视频画面呼应才有意义 (当然服务端会存档)
简单点讲,弹幕消息就是一种群消息,所以技术界是将弹幕归类为 IM(即时通讯) 范畴,它背后是实时消息。弹幕是实时消息中能被用户看到的内容,还有一部分是系统消息,用来主动触发业务逻辑、行为等。
在直播界,弹幕是一个举足轻重的角色,作为视觉和信息的直接载体,它身上承接了极重的业务形态:
- 广播出和画面内容呼应的内容
- 弹幕内容根据用户身份做特殊呈现 (给了钱的更显眼)
- 弹幕触发其他业务,例如抽奖
- 内容、频率要做管控
type Bullet struct {
ID string // 弹幕唯一ID,用于去重/追踪
UserId int // 用户ID
Nickname string // 用户昵称(展示用,可缓存)
Content string // 文本内容
Timestamp int64 // 绝对时间戳(发出时的毫秒)
Offset int // 相对直播/视频的时间(秒或毫秒,方便回放)
Extra *Extra // 样式 & 效果(颜色、位置、动画等)
// 扩展
RoomId int // 所属直播间/视频ID
Type string // 弹幕类型: text/gift/like/emoji/system
FontSize int // 字体大小
Color string // 颜色值,如 "#FF0000"
Position string // 位置: top/bottom/scroll
Device string // 发送设备信息 (web/ios/android)
IsVip bool // 是否会员/大航海
IsAdmin bool // 是否管理员/房管
IsPinned bool // 是否置顶/特殊弹幕
}
1.1 挑战和需求
直播弹幕是一个读写 QPS 要求都很高,假设一个直播间有 100w 用户同时在线观看,假设弹幕的提交频率为有 10000条/秒,那么需要每秒同时推送给在线用户的次数为 100w * 10000。由此可见,读请求的吞吐量需要远大于写请求,这点类似于 IM 实时聊天。
架构设计考虑以下几个场景:
- 支持直播弹幕回放 -> 意味着需要持久化 DB
- 用户进入直播间可以推送最新几秒的弹幕数据 -> 意味着需要多级缓存
- 长连模式和短连模式可以做降级切换 -> 保证高可用
- 尽可能地减少消息体的大小,节省带宽 -> 批请求 + 消息体压缩
其实这也是 IM 的主要挑战。
02 系统架构
2.1 MVP 版本
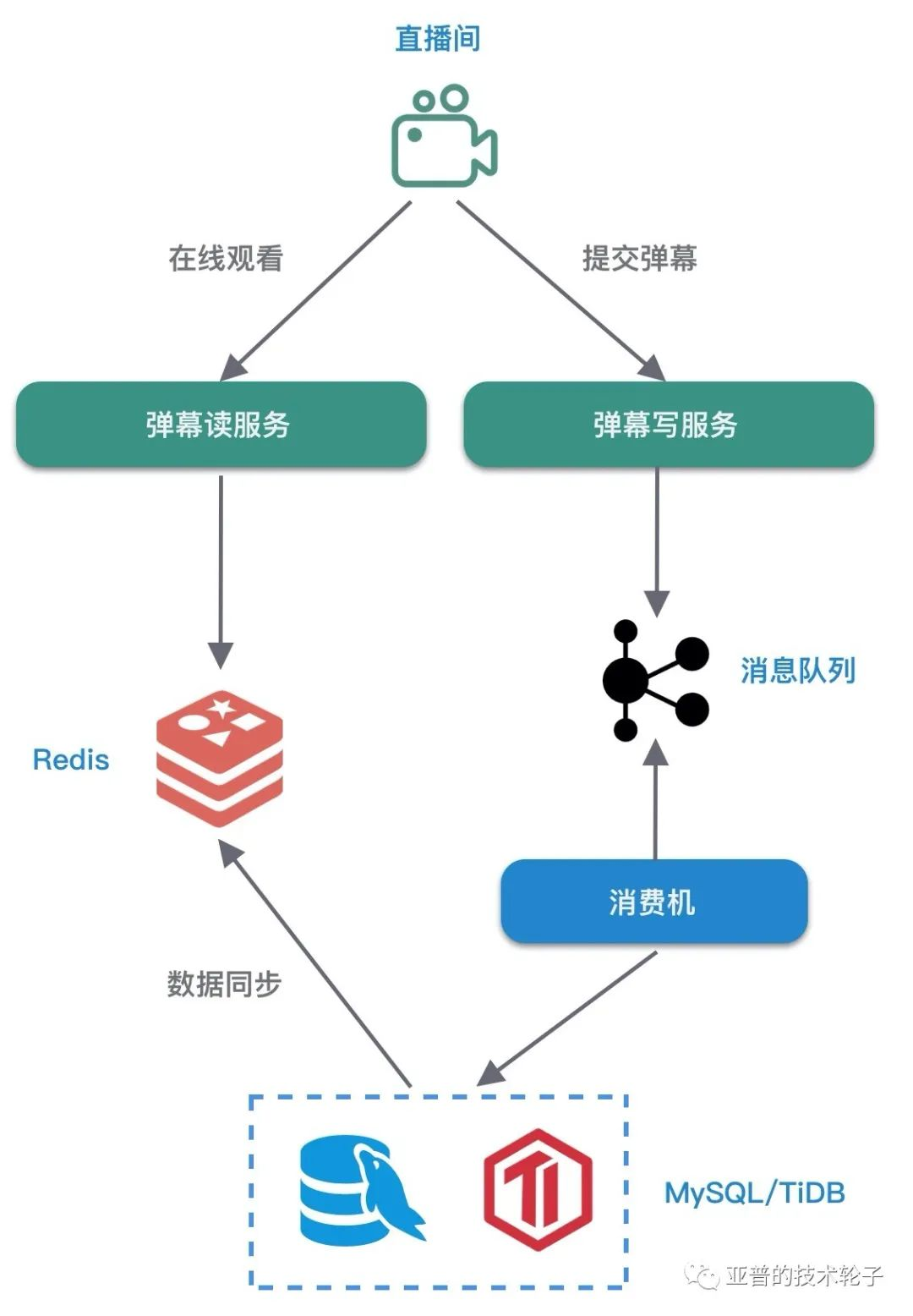
为了不影响读写的性能,采用读写分离架构。
-
写服务
- 若不考虑历史弹幕可回放,可以直接使用 Redis 作为唯一存储。
- 若考虑支持弹幕的回放,数据还是需要持久化,可以考虑使用 MySQL 或者 TiDB,暂且认为写入不是较大的瓶颈。
- 如果有更高性能的写需求,HBase、OpenTSDB 等都可以解决问题。
-
读服务
- Redis 主要用于读缓存,缓存直播间最新的弹幕数据,采用直播间 ID 作为 Key。
- 系统读服务最大 QPS = Redis 集群QPS。
Redis 存储结构选择 -> SortedSet
- 提交弹幕:
ZADD. score 设置为时间戳。进一步优化可以只存储时间的 delta 值,减少数据存储量。 - 弹幕查询:
ZRANGEBYSCORE定时轮询弹幕数据。
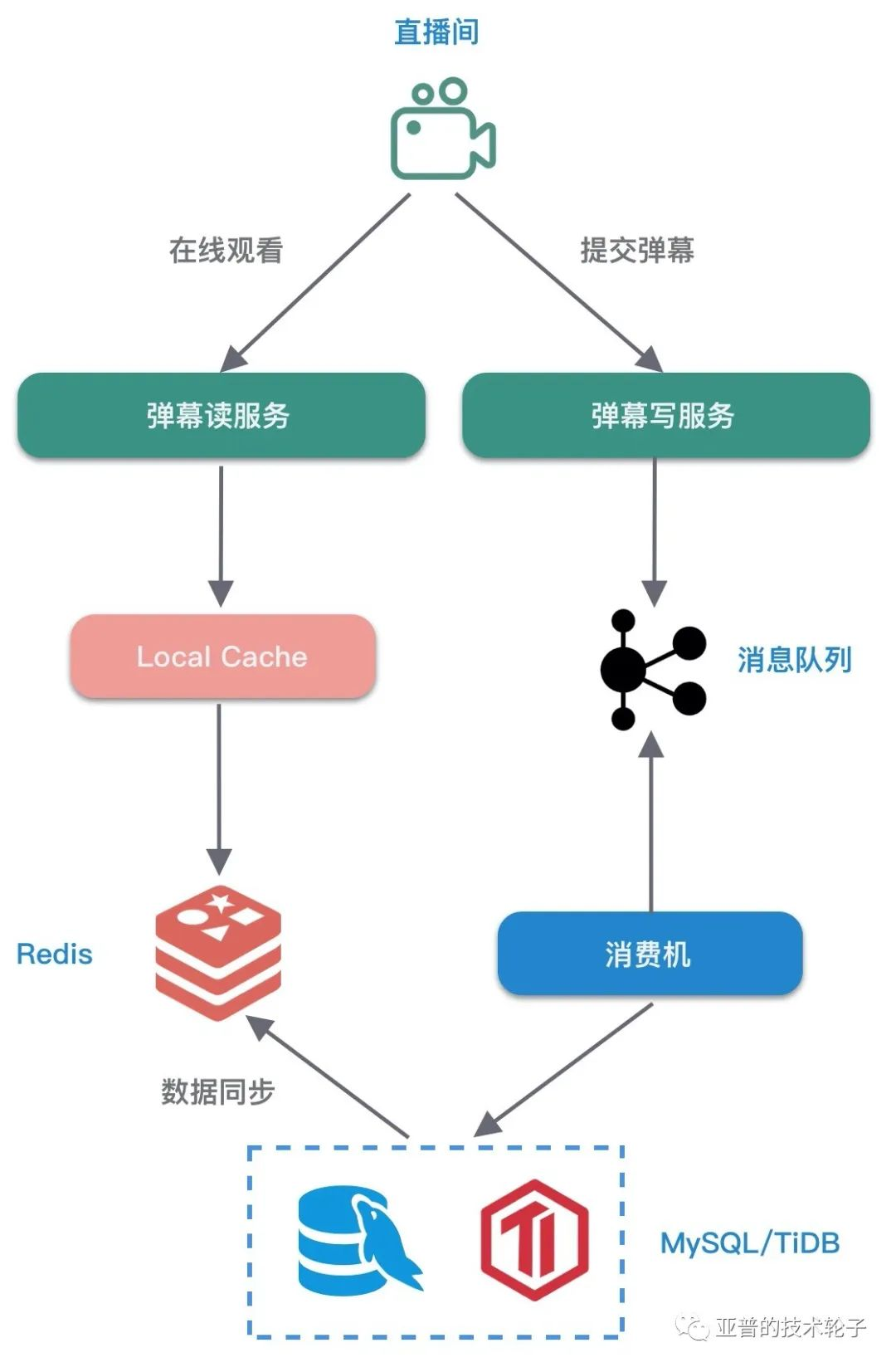
2.2 缓存优化
如果能让最新的实时弹幕数据都能命中本地缓存,那性能是最高的,同时大幅度降低了 Redis 的读取压力。所以弹幕读服务可以每秒轮询 Redis 数据,构建本地缓存。
热点问题
- 假设同时在线的直播间有 10000 个,读服务机器有 50 台,那么每秒轮询 Redis 的 QPS = 10000 * 50 = 50w,读取请求线性膨胀。
- 本地内存的使用量也随直播间的数量增长而膨胀,每个直播间的缓存的数据量降低,导致本地缓存的命中率降低,容易导致 GC 频繁。
2.3 热点优化
如何降低本地缓存的使用量?
- 因为火爆的直播间会占据整个平台大部分的流量,可以只针对火爆的直播间开启本地缓存。
- 通过 路由控制 同一个直播间的请求分发到固定的几台机器,例如一致性 Hash 算法。通过减少读服务机器上的直播间数量,达到降低本地缓存使用量的目的。
2.4 客户端长连接推送
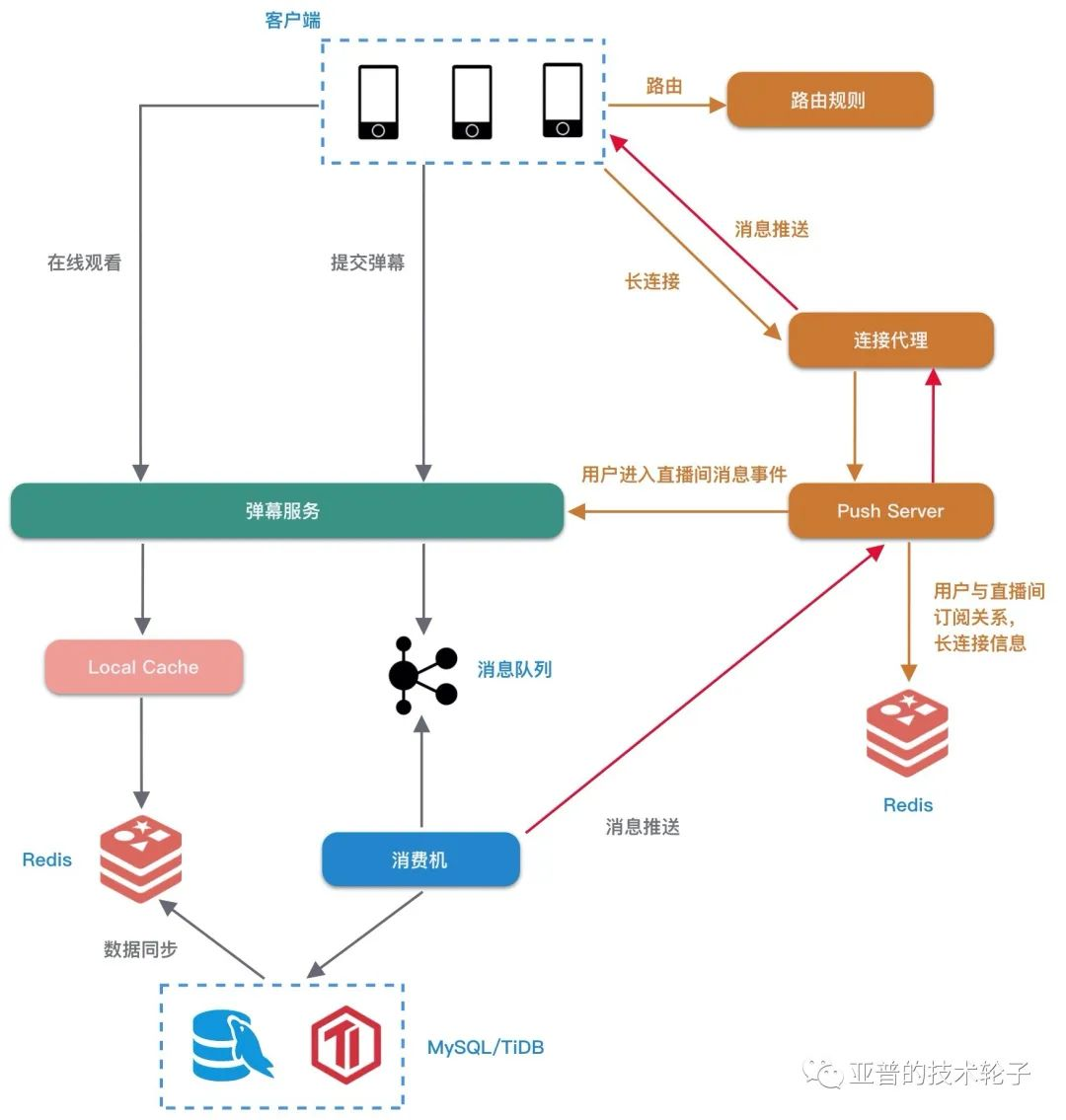
为了保障客户端消息的推送性能和实时性,长连接基本是必备的,最新的消息可以直接采用长连接实时推送。
- Push Server 从 Redis 中获取用户和直播间的订阅关系以及长连接信息。
- 连接代理只负责与客户端保持长连接。
- 海量的消息推送需要批量压缩。
04 Deep Dive - 本地缓存技术方案
4.1 方案目标
通过读服务节点本地内存缓存热点直播间最新弹幕,减少分布式缓存(Redis)轮询压力,降低网络开销,提升弹幕查询响应速度,支撑高并发读场景。核心平衡 性能、内存成本、数据实时性 三大维度。
4.2 方案设计 - 缓存数据模型
本地缓存无需存储直播间全量弹幕(全量依赖 Redis/DB),仅需缓存最近 N 条实时弹幕(如最近 10 秒、50 条,可按业务配置),且需剔除冗余字段以节省内存。
// 本地缓存用的轻量弹幕结构体(剔除存储/追溯字段,保留展示核心信息)
type LocalCacheBullet struct {
Content string // 核心文本内容
Nickname string // 展示昵称(已脱敏/格式化)
Timestamp int64 // 发送时间戳(用于排序/过期)
// 样式字段按需保留,避免大字段(如Color可存16进制短码,而非完整字符串)
Color uint32 // 颜色用uint32存储(如0xFF0000替代"#FF0000")
FontSize int8 // 字体大小用int8(仅几种可选值)
Position int8 // 位置用枚举值(0:scroll,1:top,2:bottom)
}
4.3 方案设计 - 本地缓存结构
本地缓存需支持快速插入、范围查询、过期清理,且需保证多线程安全 -> 读服务可能多协程处理用户请求。
工程首选: 环形缓冲区 -> 平衡性能与内存
- 用固定长度的切片(如cap=50)存储弹幕,尾部插入新数据,满了则覆盖头部旧数据
- 用
RWMutex做读写锁(读多写少场景,读锁不互斥,性能更优) - 额外记录count(实际存储条数)和latestTS(最新弹幕时间戳),方便快速判断是否需要更新
- 插入 / 查询
O(1),内存连续,GC 压力小
4.4 数据同步 - Pull Model
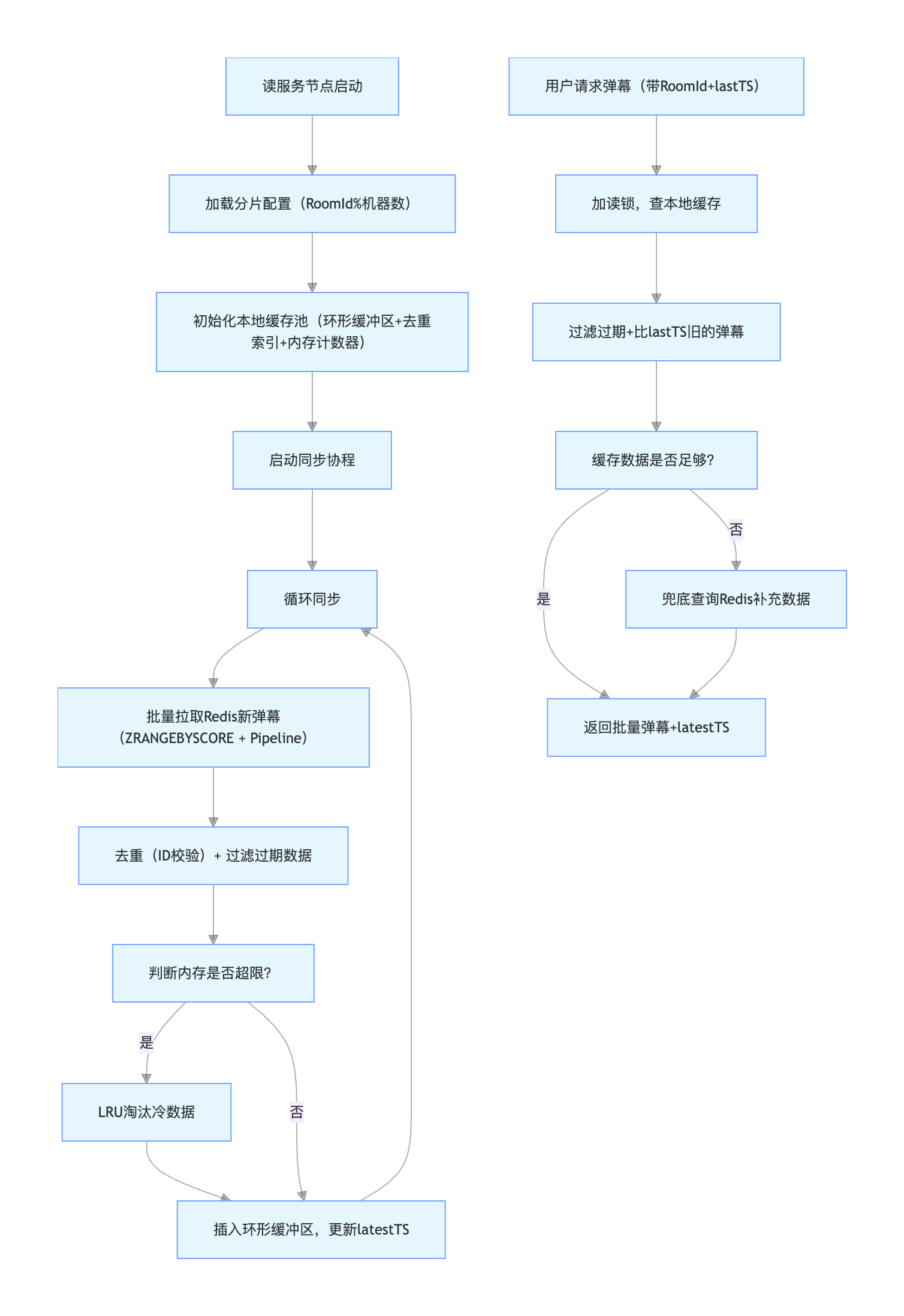
本地缓存的数据来源于分布式缓存 Redis,同步机制是核心,需解决 "轮询压力、数据一致性、更新效率" 问题。
4.4.1 同步模式: "主动拉取 + 批量合并" 替代 "单直播间轮询"
针对 “10000 个直播间 + 50 台机器 = 50w Redis QPS” 的轮询膨胀问题,采用 直播间分片 + 批量拉取 策略
- 直播间分片绑定
- 给读服务集群的每个节点分配固定的 “直播间分片”(如按
RoomId % 机器数分片),每个节点仅负责自己分片内的直播间缓存更新. - 例:50 台机器,RoomId=1001 → 1001%50=1 → 仅由节点 1 负责同步该直播间的缓存.
- 优势:轮询 QPS 从
直播间数×机器数降至直播间数,彻底解决轮询膨胀.
- 给读服务集群的每个节点分配固定的 “直播间分片”(如按
- 批量拉取 Redis 数据
- 每个节点按分片聚合直播间,批量执行 Redis 的
ZRANGEBYSCORE(SortedSet 按时间戳查最新数据),而非单直播间单独查询; - 例:节点 1 负责 100 个直播间,每 1 秒执行 100 个
ZRANGEBYSCORE key latestTS +inf(仅查上次同步后的新数据),而非 100 次单独请求。 - 优化:使用 Redis Pipeline 批量发送命令,进一步减少网络往返开销。
- 每个节点按分片聚合直播间,批量执行 Redis 的
4.4.2 同步频率 - 动态调整 避免无效轮询
同步频率并非固定 1 秒,需结合直播间热度动态调整。读服务节点维护 直播间热度表(记录每个直播间的在线人数 / 弹幕频率),每 5 秒更新一次热度等级
- 热点直播间 如
10w +在线:- 同步频率 100ms~500ms(保证实时性)
- 中冷直播间
1000~10w在线:- 同步频率 1s~2s
- 冷直播间
<1000在线- 同步频率
5s~10s,甚至 “有新弹幕才触发更新” - 通过 Redis 的KEYSPACE_NOTIFY事件优化
- 同步频率
4.4.3 数据合并 - 去重 + 增量更新
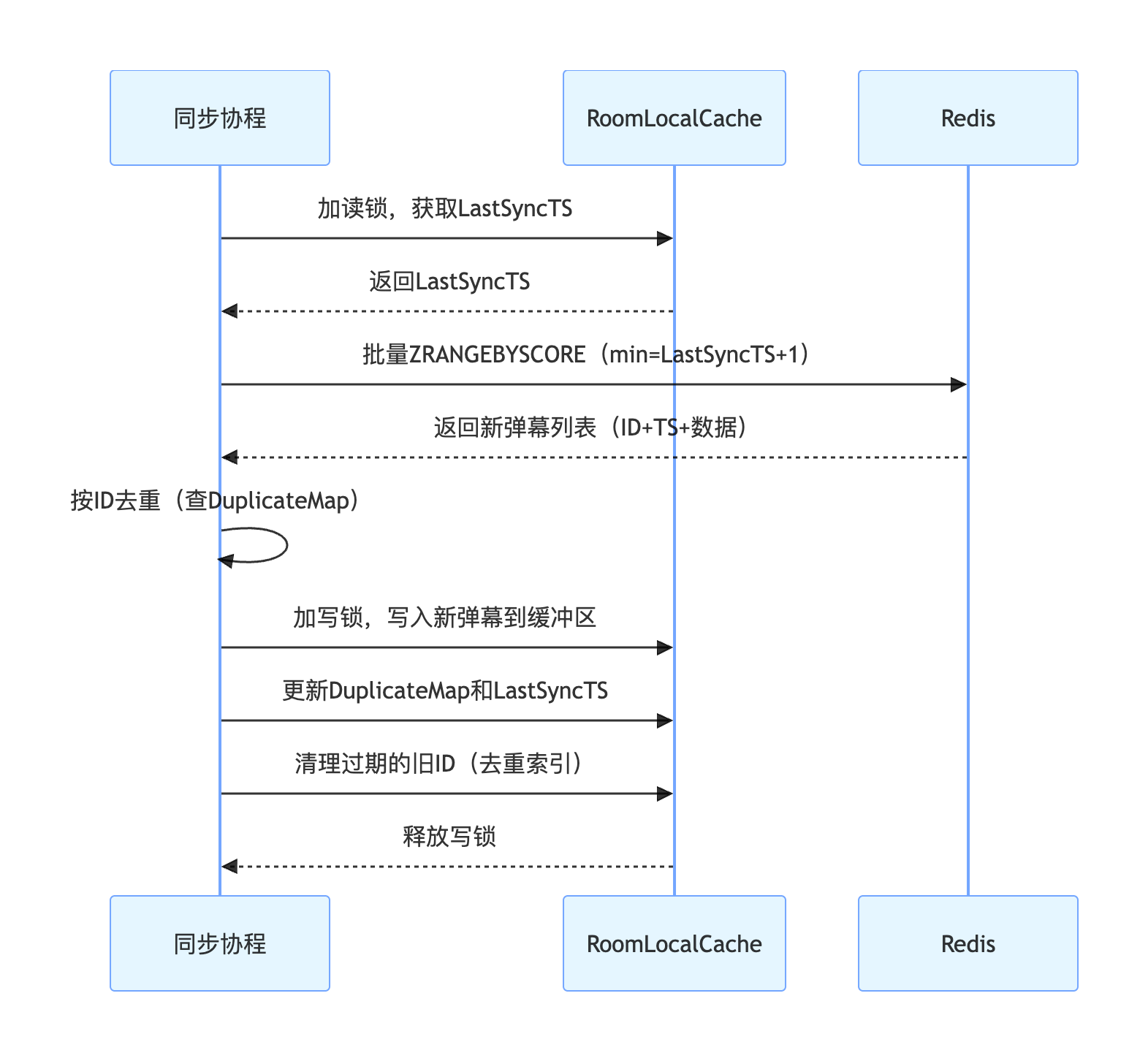
增量更新的核心逻辑是:仅从 Redis 拉取 “上次同步后新增的弹幕”,并过滤掉重复数据,最终只将真正的新弹幕写入本地缓存。整个流程可拆解为 增量拉取 -> 精准去重 -> 安全写入 三个核心步骤,以下是工程级具体实现细节。
为实现增量更新,每个直播间的本地缓存需维护 3 个核心状态
// 单个直播间的本地缓存实体
type RoomLocalCache struct {
Buffer *RingBuffer // 环形缓冲区(存弹幕数据)
DuplicateMap map[string]bool // 去重索引(key:弹幕唯一ID)
LastSyncTS int64 // 上次从Redis拉取数据的最大时间戳
RWMutex sync.RWMutex // 读写锁(保护上述字段)
}
同步协程针对分片内的每个直播间,按以下规则构造 Redis 查询参数
- Key: 直播间弹幕的 Redis 键(如bullet:room:1001)
- MinScore: LastSyncTS + 1(仅拉取比上次更新更新的弹幕,避免重复拉取)
- MaxScore: 当前时间戳(拉取截止到此刻的所有新弹幕)
- Limit: 0, 100(单次拉取上限 100 条,避免单批数据过大阻塞同步)
// 伪代码:批量拉取某分片内的直播间新弹幕
pipeline := redisClient.Pipeline()
for _, roomCache := range shardRoomCaches {
roomCache.RLock() // 读锁,不阻塞用户查询
lastTS := roomCache.LastSyncTS
roomCache.RUnlock()
// 构造命令:ZRANGEBYSCORE key min max WITHSCORES LIMIT 0 100
cmd := pipeline.ZRangeByScoreWithScores(
fmt.Sprintf("bullet:room:%d", roomId),
&redis.ZRangeBy{
Min: strconv.FormatInt(lastTS+1, 10),
Max: strconv.FormatInt(time.Now().UnixMilli(), 10),
Count: 100,
},
)
// 绑定房间ID与命令结果,后续处理
pendingCmds[roomId] = cmd
}
// 执行批量查询
_, err := pipeline.Exec()
解析 Redis 返回结果,转换为 “弹幕 ID + 时间戳 + 原始数据” 的结构化列表。
针对拉取到的弹幕列表,通过 “两层校验” 过滤重复数据,确保写入缓存的弹幕唯一。
- 第一层 -> 基于 弹幕ID 去重
- 这是最核心的去重逻辑,利用
DuplicateMap快速判断
- 这是最核心的去重逻辑,利用
- 第二层 -> 极端场景兜底去重
- 若弹幕 ID 生成逻辑存在漏洞(如 ID 重复),可增加
UserId + Timestamp兜底 - 组合key 精确到毫秒,避免同一用户同一时刻发多条的重复
- 若弹幕 ID 生成逻辑存在漏洞(如 ID 重复),可增加
// 伪代码:去重逻辑
var newBullets []LocalCacheBullet
var maxTS int64 = roomCache.LastSyncTS
for _, bullet := range redisBullets {
// 1. 校验弹幕ID是否已在本地缓存中
if roomCache.DuplicateMap[bullet.ID] {
continue // 已存在,跳过
}
// 2. 记录当前批次的最大时间戳(用于更新LastSyncTS)
if bullet.Timestamp > maxTS {
maxTS = bullet.Timestamp
}
// 3. 转换为轻量本地缓存模型,加入新弹幕列表
newBullets = append(newBullets, convertToLocalModel(bullet))
}
// 生成组合唯一键(UserId+Timestamp精确到毫秒,避免同一用户同一时刻发多条的重复)
comboKey := fmt.Sprintf("%d_%d", bullet.UserId, bullet.Timestamp)
if roomCache.DuplicateMap[bullet.ID] || roomCache.DuplicateMap[comboKey] {
continue
}
// 同时将ID和组合键存入去重索引(双重保障)
roomCache.DuplicateMap[bullet.ID] = true
roomCache.DuplicateMap[comboKey] = true
仅将去重后的新弹幕写入环形缓冲区,并同步更新 LastSyncTS 和 DuplicateMap,保证状态一致性。
- 1.加写锁保护写入
- 由于同步协程和用户查询协程可能同时操作缓存,需加写锁确保原子性
- 2.写入环形缓冲区
- 将
newBullets列表按时间戳顺序插入环形缓冲区(若 Redis 返回无序,需先排序)
- 将
- 3.更新同步状态
- 将
LastSyncTS更新为当前批次的最大时间戳,确保下次拉取从正确的起点开始
- 将
- 4.清理过期去重索引 -> 防内存泄漏
DuplicateMap会随弹幕增多而膨胀,需同步清理 “已从环形缓冲区淘汰的旧弹幕 ID”
// 方法1:基于时间窗口清理(推荐)
expireTS := time.Now().UnixMilli() - 10*1000 // 清理10秒前的旧ID
for id := range roomCache.DuplicateMap {
// 从缓冲区中查询该ID对应的弹幕时间戳(或在DuplicateMap存ID→TS的映射)
if bulletTS, exists := roomCache.IdToTSMap[id]; exists && bulletTS < expireTS {
delete(roomCache.DuplicateMap, id)
delete(roomCache.IdToTSMap, id)
}
}
// 方法2:基于缓冲区大小清理(简单)
if len(roomCache.DuplicateMap) > roomCache.Buffer.Capacity()*2 {
// 当索引大小超过缓冲区容量2倍时,清空并重建(依赖缓冲区中的弹幕ID)
newDuplicateMap := make(map[string]bool, roomCache.Buffer.Capacity())
for _, bullet := range roomCache.Buffer.All() {
newDuplicateMap[bullet.ID] = true
}
roomCache.DuplicateMap = newDuplicateMap
}
4.4.4 异常处理与边界场景
-
网络重试导致的重复拉取
- 若 Redis 查询超时后重试,可能导致同一批弹幕被多次拉取。
- 此时
DuplicateMap会直接过滤重复 ID,且LastSyncTS未更新(因拉取的弹幕时间戳≤当前LastSyncTS),不会重复写入。
-
直播间热度突变(冷→热)
- 当冷流直播间突然变为热点(如开播),
LastSyncTS可能滞后较久,首次拉取会返回大量历史弹幕。此时: - 单次拉取按
Limit 0 100分批处理,避免阻塞; - 环形缓冲区会覆盖旧数据,仅保留最新 N 条,符合 “本地缓存聚焦实时” 的目标。
- 当冷流直播间突然变为热点(如开播),
-
节点重启后的初始化
- 节点重启后,
LastSyncTS重置为 0,首次拉取会获取该直播间最近的弹幕 (如 Redis 中保留的最近 100 条) - 批量写入缓冲区并重建
DuplicateMap - 后续同步恢复正常增量逻辑
- 节点重启后,
4.5 数据同步 - Push Model
在本地缓存(Pull 模型)基础上,对高热度直播间(如在线超 10 万)新增 Push 主动推送能力,减少客户端轮询开销,将弹幕实时性从 “秒级” 压缩到 “百毫秒级”,同时保留 Pull 模型对冷流直播间的成本优势。
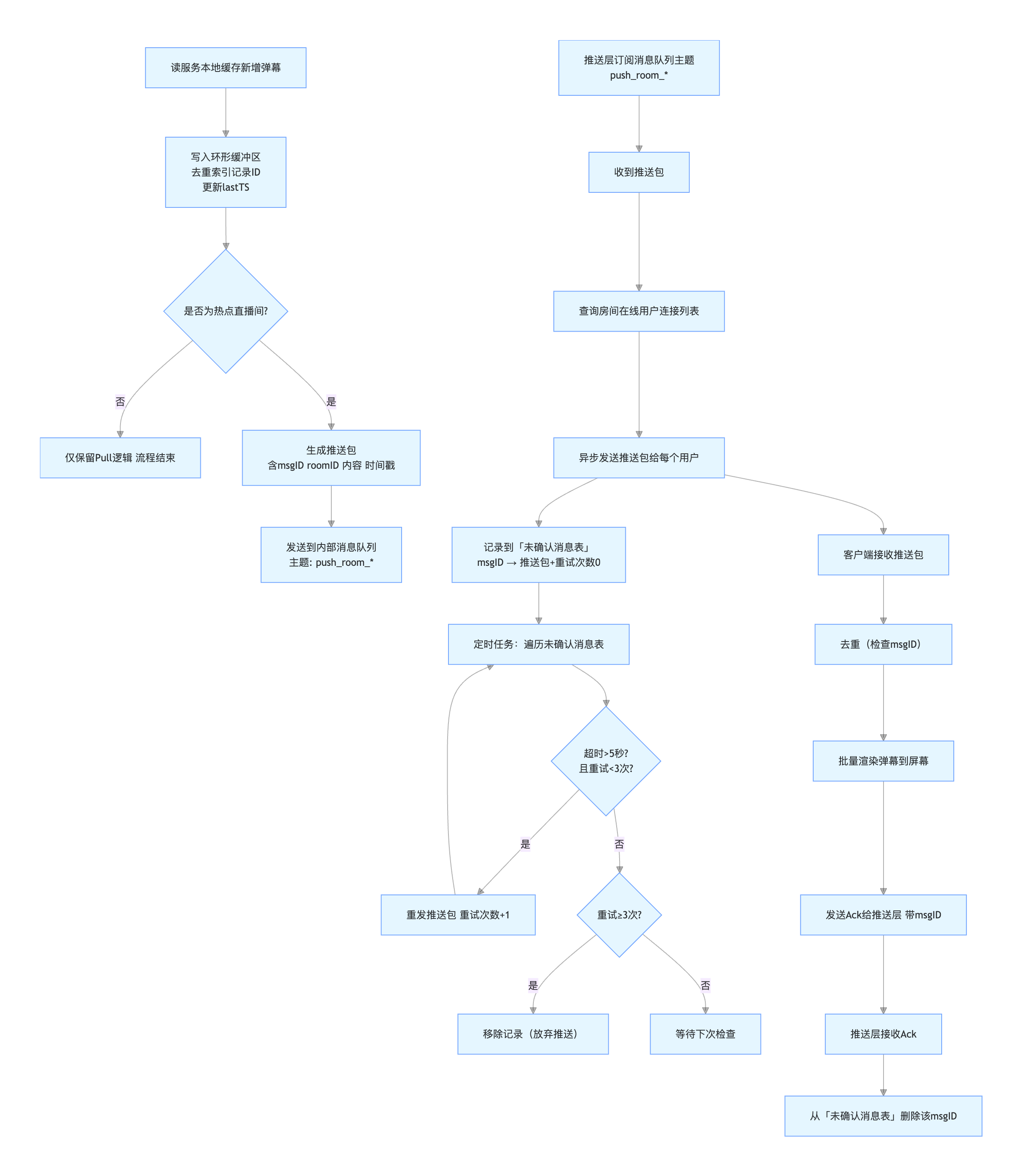
4.5.1 拓扑与路由
- 入口聚合
- 写服务将每条弹幕写入 MQ
- 按 roomId 做一致性分区,保证同房间同�分区。
- 分片消费
- 消息分发层维护
roomId -> edge shard映射 - 每个读节点仅订阅自己负责的房间分片分区。
- 消息分发层维护
- 更新服务器本地缓存
- 读节点消费到“房间帧(frame)/增量消息”后直接写入 RoomLocalCache 即 Server的本地缓存
- 随后广播到所有连接到这台 Server的客户端的 send buffer。
send buffer 定义
- 就是一个待发送消息队列,绑定在每个客户端长连接上。
- Push 线程把要发给该用户的弹幕帧放入队列,而不是立刻写 socket。
- 专门的 写线程/协程 会从队列里取数据,**批量 flush(writev/io_uring)**到网络。
- 假设房间里有 10 万个用户,读节点拉到一帧新弹幕后,会遍历房间内的所有连接,将这帧数据拷贝/引用到每个连接的 send buffer 中。
- 这样每个连接都有一个 send buffer as 中间缓存队列,保证消息不会因为 socket 写阻塞而影响全局。
- flush 时把队列里多条消息合并成一个大包,减少系统调用。
4.5.2 核心链路和服务流程
1.服务端 - 热点直播间识别与标记// 读服务节点定期更新直播间热度
function 刷新直播间热度() {
遍历所有分片内的直播间:
从统计服务获取 在线人数、弹幕频率
if 在线人数 > 10万 或 弹幕频率 > 100条/秒:
标记为"Push优先"
else:
维持"Pull优先"
}
// 本地缓存新增弹幕时的处理逻辑
function 本地缓存_新增弹幕(roomID, 新弹幕):
// 1. 写入环形缓冲区(原Pull逻辑)
环形缓冲区.添加(新弹幕)
去重索引.记录(新弹幕.ID)
更新最后同步时间戳
// 2. 若为热点直播间,触发Push
if 直播间[roomID].类型 == "Push优先":
生成推送包 = {
msgID: 全局唯一ID,
roomID: roomID,
弹幕内容: 新弹幕,
时间戳: 当前毫秒数
}
发送到内部消息队列(主题: "push_room_" + roomID)
// 推送层:处理待推送弹幕
function 推送层_消息处理():
订阅"push_room_*"主题:
收到推送包时:
查房间对应的在线用户连接列表
对每个连接:
Async 异步发推送包
记到未确认表(存msgID、推送包、重试次数0)
// 推送层:重试没收到确认的消息
function 推送层_重试未确认消息():
遍历未确认表:
if 消息超时>5秒 且 重试<3次:
重发消息,重试次数+1
else if 重试≥3次:
删掉这条记录(放弃)
// 推送层:收到客户端确认
function 推送层_接收Ack(msgID):
从未确认表删掉该msgID
// 客户端接收推送
function 客户端_处理推送(推送包):
// 1. 去重
if 本地去重集合.包含(推送包.msgID):
return
本地去重集合.添加(推送包.msgID)
// 2. 加入渲染队列(批量渲染优化)
渲染队列.添加(推送包.弹幕内容)
if 渲染队列.长度 >= 20 或 距上次渲染已过50ms:
批量渲染弹幕(渲染队列)
清空渲染队列
// 3. 回复Ack
发送Ack到服务端(msgID)
4.6 内存管控 - 避免 OOM 与 GC 风暴
本地缓存本质是 “用内存换性能”,若不加管控会导致内存泄漏或 GC 频繁,需从 “容量、过期、淘汰” 三方面限制。
- 1.单节点缓存总量上限
- 按机器内存配置全局上限(如单节点内存 8G,分配 1G 给本地缓存);
- 按直播间分配内存配额:热点直播间配额 50 条,冷直播间配额 20 条,避免单个直播间占用过多内存;
- 维护 “缓存内存计数器”,每插入一条弹幕累加内存占用(按结构体大小估算),达到上限时触发全局淘汰。
- 2.数据过期策略: 时间窗口 + 惰性删除
- 主动过期 -> 同步线程每轮询时,清理环形缓冲区中 “超过缓存窗口” 的旧数据(如缓存窗口 10 秒,删除
Timestamp < 当前时间-10s的弹幕); - 惰性删除 -> 用户请求查询弹幕时,先过滤掉过期数据再返回,避免返回无效数据。
- 主动过期 -> 同步线程每轮询时,清理环形缓冲区中 “超过缓存窗口” 的旧数据(如缓存窗口 10 秒,删除
- 3.淘汰策略:针对冷数据优先释放
- 当内存达到上限,采用 LRU (最近最少使用) + 热度加权 淘汰
- 为每个直播间的缓存记录
lastAccessTime(最后一次被用户查询的时间) - 淘汰时优先选择 “lastAccessTime最早、热度最低” 的直播间缓存,清空其环形缓冲区和去重索引
- 优势:保留热点数据,释放冷数据内存,最大化缓存命中率
05 B站 - 千万长连消息系统
长连接,顾名思义,是应用存活期间和服务端一直保持的网络数据通道,能够支持全双工上下行数据传输。其和请求响应模式的短连接服务最大的差异,在于它可以提供服务端主动给用户实时推送数据的能力。
本文将介绍基于 Golang 实现的长连接服务,介绍长连接服务的框架设计,以及针对稳定性与高吞吐做的相关优化。
TCP 协议: 支撑 “可靠型” 长连接 (弹幕、互动消息)
TCP 是面向连接、可靠传输的协议(有三次握手建立连接、重传机制、流量控制),适合传输 “不能丢、不能错” 的数据。在直播中,TCP 主要通过 WebSocket 协议封装,实现 “全双工、长连接” 的信令和互动消息传输。
- 信令交互: 比如观众点击 “进入直播间”,客户端会通过 WebSocket 长连接向服务器发送 “加入房间” 信令;服务器收到后,返回 “房间信息(如当前在线人数、画质选项)”,并维持这个连接,后续的 “切换画质”“退出房间” 等指令都通过这个连接传输。为什么用 WebSocket?因为 HTTP 是 “短连接、请求 - 响应” 模式,无法主动推送数据;而 WebSocket 基于 TCP 握手后,能实现 “服务器主动向客户端推数据”(比如主播开播后,服务器主动通知订阅用户 “主播已上线”),且连接会长期保持(除非断网或主动关闭),符合 “长连接” 需求。
- 互动消息: 弹幕、礼物通知等数据量小但需要实时性 —— 比如用户发一条弹幕,客户�端通过 WebSocket 长连接发送给服务器,服务器再通过该连接将弹幕推送给房间内所有在线观众。由于 TCP 可靠,弹幕不会丢失(不会出现 “发了但别人看不到” 的情况)。
UDP 协议: 支撑 “低延迟型” 长连接 (音视频流)
UDP 是无连接、不可靠传输的协议(没有握手、没有重传,数据发出去就不管了),但优势是速度快、延迟低(省去了 TCP 重传、流量控制的耗时),适合传输 “可容忍少量丢包” 的音视频数据(比如偶尔丢一个视频帧,观众可能只看到瞬间卡顿,不影响整体观看)。 在直播中,UDP 不会 “裸用”,而是会封装到更上层的音视频传输协议中,常见的有 RTMP、RTSP、QUIC。
- RTMP (Real-Time Messaging Protocol): 早期直播(如秀场直播)的主流协议,基于 TCP 或 UDP 实现(但实际应用中更常用 TCP,因为早期网络稳定性差,TCP 的可靠性能减少卡顿)。RTMP 会将音视频数据切片成 “小数据包”,通过长连接持续传输,适合 “标清 - 高清” 画质的实时推流 / 拉流。
- RTSP (Real-Time Streaming Protocol): 更偏向 “实时性要求极高” 的场景(如直播带货、游戏直播),基于 UDP 实现。RTSP 不负责数据传输本身,而是通过 “控制指令”(如 “播放”“暂停”)协调 UDP 连接传输音视频,延迟可低至 100-300ms(比 RTMP 快)。
- QUIC (Quick UDP Internet Connections): 近几年主流的 “低延迟直播协议”(如抖音、快手的直播),基于 UDP 封装,但解决了 UDP 的 “不可靠” 问题 ——QUIC 自带 “重传、流量控制、加密” 功能,既保留了 UDP 的低延迟优势,又具备 TCP 的可靠性,延迟可压缩到 100ms 以内,同时能应对弱网络(如 4G 切换 WiFi 时,连接不中断)。
| 连接类型 | 传输的数据内容 | 核心需求 | 常用协议 |
|---|---|---|---|
| 1. 信令长连接 | 开播/关播指令、房间进入/退出、画质切换(如高清→标清)、连麦请求等控制指令 | 可靠传输(指令不能丢)、低延迟 | TCP(WebSocket) |
| 2. 音视频流长连接 | 主播的视频画面、声音(推流阶段);观众接收的实时音视频(拉流阶段) | 低延迟(避免卡顿/延迟)、高吞吐(支撑高清画质) | UDP(RTSP/RTMP/QUIC) |
| 3. 互动消息长连接 | 弹幕、礼物通知、点赞、评论实时刷新等互动数据 | 低延迟、轻量(数据量小但频次高) | TCP(WebSocket)/UDP(QUIC) |
5.1 框架 - 整体架构
长连接服务是多业务方共同使用一条长连接。因为在设计时,需要考虑到不同业务方、不同业务场景对长连接服务的诉求,同时,也要考虑长连接服务的边界,避免介入业务逻辑,影响后续长连接服务的迭代和发展。
长连接服务主要分为三个方面:
- 长连接建立、维护、管理
- 下行数据推送
- 上行数据转发(目前只有心跳,还没实际业务场景需求)
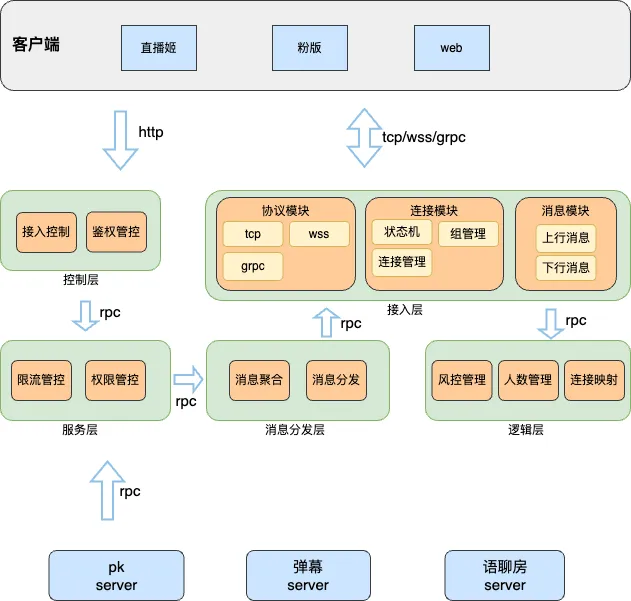
长连接服务整体构架如上图所示,整�体服务包含:
- 控制层: 建连的前置调用,主要做接入合法性校验、身份校验和路由管控
- 用户身份鉴权。
- 加密组装数据,生成合法token。
- 动态调度分配接入节点。
- 接入层: 长连接核心服务,主要做卸载证书、协议对接和长连接维护
- 卸载证书和协议。
- 负责和客户端建立并维护连接,管理连接id和roomid的映射关系。
- 处理上下行消息。
- 逻辑层: 简化接入层,主要做长连的业务功能
- 在线人数上报记录。
- 记录连接ID各属性和各节点的映射关系。
- 消息分发层: 消息推送到接入层
- 消息封装、压缩和聚合推送给相应的边缘节点。
- 服务层: 业务服务对接层,提供下行消息推送入口
- 管控业务推送权限。
- 消息检测和重组装。
- 消息按一定策略限流,保护自身系统。
卸载证书 Certificate Offloading
- 这里的“证书”指的是 SSL/TLS 证书(HTTPS、WSS 里的加密证书)
- 卸载证书就是把 加解密的计算工作 从业务层移到 接入层(或负载均衡/网关层)。
- 客户端连上来时,接入层负责做 TLS 握手、解密。
- 后端逻辑层收到的就是明文数据,不需要每台业务服务器都装证书。
- 好处
- 避免业务服务都去处理耗时的 TLS 运算。
- 统一管理证书,降低复杂度。
👉 举例 像 Nginx/Envoy 这种反向代理,通常就做 TLS offloading,把 HTTPS 终止在接入层,后端内部走明文 HTTP。
协议卸载 Protocol Offloading
- 这里的协议通常指 WebSocket / QUIC / TCP 自定义协议。
- 卸载 就是在接入层处理 底层协议细节,然后把业务层只需要的 简化后的数据 往上游转。
- 例如:接入层和客户端保持 WebSocket 长连
- 在逻辑层,上游服务只接收“用户发送了一条弹幕消息”的业务事件,而不用关心 WebSocket 心跳、帧解析等细节。
- 好处
- 把复杂、耗资源的连接管理和协议细节集中处理。
- 上游业务逻辑可以专注做功能,而不用实现一堆通信协议。
5.2 框架 - 核心流程
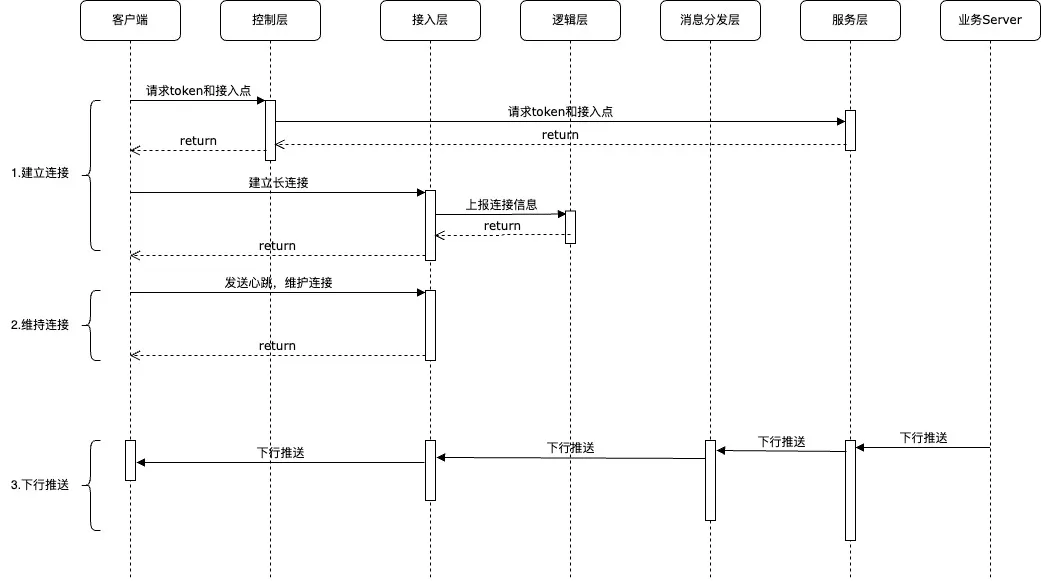
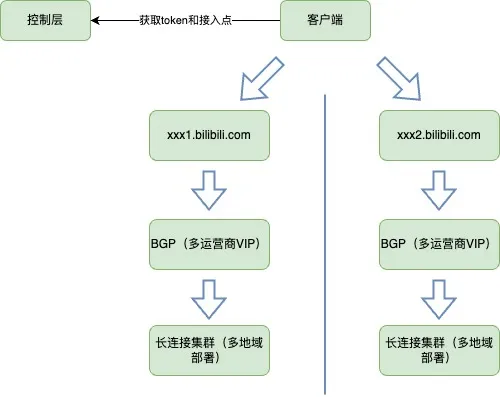
- 建立连接
- 由客户端发起,先通过控制层,获取该设备合法的token和接入点配置。
- 维持连接
- 主要是客户端定时发起心跳,来保证长连接活跃。
- 下行推送
- 下行推送由业务Server发起,经由服务层根据相关标识确定连接标识和接入节点,经过消息分发层,把推送到对应的接入层,写入到指定连接上,然后下发到客户端。
5.3 框架 - 典型业务场景
结合B站业务场景,下行数据推送,提供如下通用功能
- 用户级消息 -> 指定推送给某些用户。比如给某个主播发送邀请pk消息。
- 设备级消息 -> 制定推送给某些设备。比如针对未登陆的设备,推送客户端日志上报指令。
- 房间级消息 -> 给某房间内的连接推送消息。比如给直播间的所有在线用户推送弹幕消息。
- 分区消息 -> 给某分区的房间推送消息。比如给某个分区下,所有开播的房间,推送某个营收活动。
- 全区消息 -> 给全平台用户推送消息。比如给全部在线用户推送活动通知。
5.4 高吞吐设计
随着业务发展壮大,在线用户越来越多,�长连系统的压力越来越大,尤其是热门赛事直播,比如 LOL S赛期间,全平台在线人数快达到千万,消息吞吐量有上亿,长连系统消息分发平均延迟耗时在 1s 左右,消息到达率达到 99%,下面具体分析下长连做了哪些措施。
5.4.1 网络协议
选择合适的网络协议对于长连接系统的性能至关重要。
- TCP协议可以提供可靠的连接和数据传输,适用于对数据可靠性要求较高的场景
- UDP协议是一个不可靠的协议,但是传输效率高,适用于对数据可靠性要求不高的场景
- 而WebSocket协议也是实现双向通信而不增加太多的开销,更多的用于web端。
接入层拆分成协议模块和连接模块。
-
协议模块和连接模块
- 和具体的通讯层协议交互,封装不同通讯协议的接口和逻辑差异。
- 同时给连接模块提供统一的数据接口,包括连接建立、数据读取、写入等。
- 后续增加新协议,只要在协议模块做适配,不影响其他模块的长连业务逻辑。
-
协议模块和连接模块
- 维护长连接业务连接状态,支持请求上行、下行等业务逻辑,维护连接各属性,以及和房间id的绑定关系。
5.4.2 负载均衡 - 就近 + 动态
- 就近原则
- 优先让客户端连接到地理位置最近的接入节点,比如北京用户连接北京的节点,广州用户连接广州的节点
- 减少跨地区网络延迟(比如从几十 ms 降到几 ms)。
- 动态调整
- 控制层会实时更新节点状态(比如某节点连接数突然增高)
- 当发现某个节点负载过高时,会自动将新的客户端请求分配到负载较低的节点,避免单一节点因过载导致延迟飙升或崩溃。
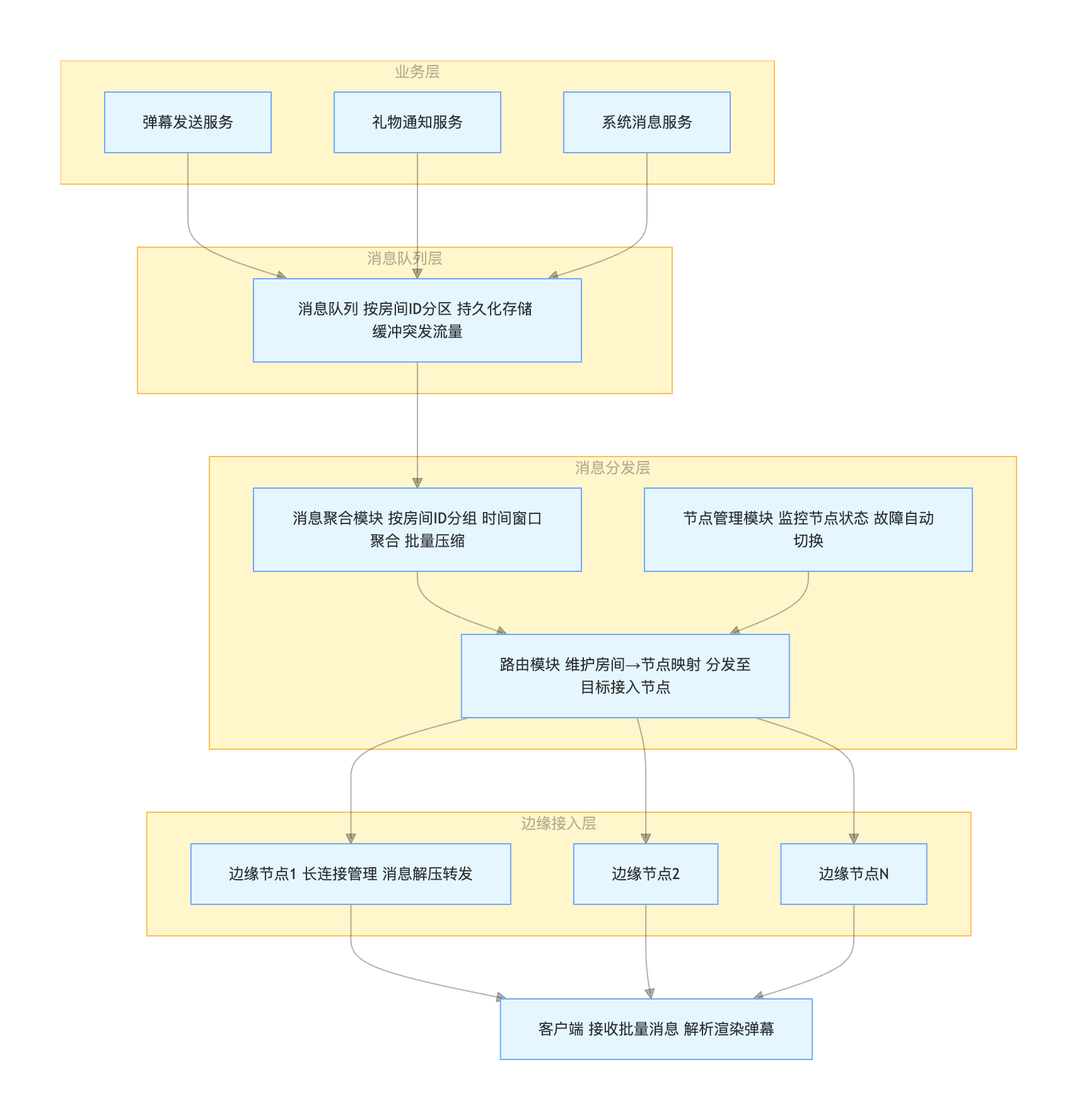
5.4.3 消息队列
如果 业务服务 直接把消息推到所有边缘节点,会有两个问题:
- 房间消息要推多个边缘节点
- 比如一个直播间的用户可能分布在全国几十个机房的接入层,那业务服务要给每个接入层都发一份,操作很重。
- 业务逻辑和消息分发混在一起
- 业务服务一边做自己的逻辑(如扣费、风控、记录日志)
- 一边还要推送海量消息 → 吞吐量和稳定性很差。
👉 解决办法
- 在业务服务和接入层之间,加一个 MQ 和 消息分发层。
- 业务服务只需要把消息丢进消息队列,不管下游的推送细节。
- 消息分发层专门消费队列里的消息,根据
房间/用户ID,把消息路由到正确的接入层。
5.4.4 消息聚合
- 假设一个超级热门房间(比如 S 赛直播),有 1000 万人同时在线。
- 如果每人每秒发一条弹幕,那系统每秒要处理
1000 万 × 1000 万 = 10^14条消息。 - 但观察发现: 这些消息都是 同一个房间里的消息 -> 实际上大家看到的内容高度重叠。
👉 解决办法
- 在 消息分发层,对同一个房间的消息做 聚合/批量处理
- 例如,把同一毫秒内的 100 条弹幕合成一个包,一次性推给接入层。
- 或者只推送代表性的部分消息(如弹幕池抽样/合并),减少扩散的消息量。
- 好处
- 减少网络包数量:假如原本需要发 1000 万条,现在聚合成 100 万个批次,就能大幅减轻接入层和带宽压力。
- 不影响业务语义:用户仍然能看到完整弹幕,只是数据传输更高效。
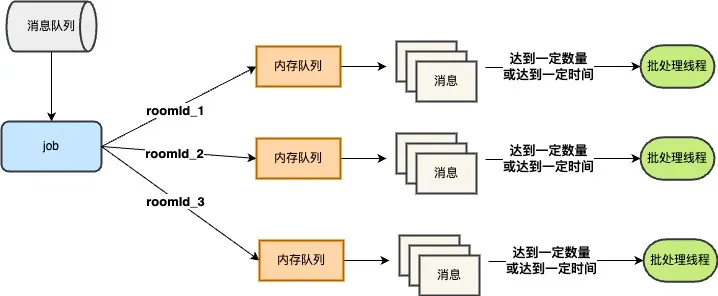
消息聚合上线后,消息分发层对接入层调用 QPS 下降60% 左右,极大的降低了接入层和消息分发层的压力。
5.4.5 压缩算法
消息聚合虽然成功减少了需要传输的消息数量,但也带来了新问题 -> 单条消息的体积变大了。这会增加数据写入存储或传输时的 IO 压力,因此必须通过压缩来减小消息体大小。
- 候选算法
zlib: 常见压缩算法,压缩率中规中矩,速度也还行。brotli: Google 推的,压缩率普遍比 zlib 更好,但压缩速度稍慢。
- 实验结论
- 在不同消息大小场景下,brotli 平均比 zlib 多省 17%~20% 的体积。
- 例如: 40 条消息,原始 19KB → zlib 压缩后
3.1KB,而 brotli 压缩后只有2.4KB - 即 相同数据��量,brotli 更省流量
5.5 服务高可用保障
5.5.1 多地多活部署
多活部署,通过在不同地理位置部署相同的系统架构和服务,实现了系统在单一地域故障时的快速故障转移,从而提高了系统的稳定性和可用性。
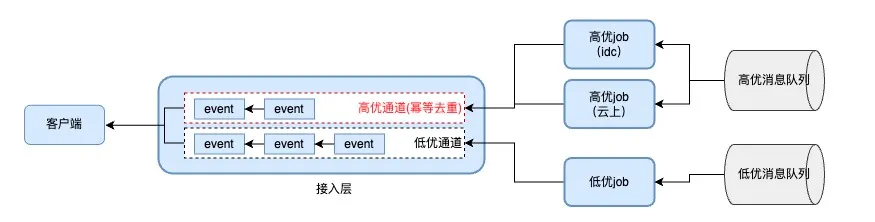
5.5.2 高低优先级消息通道
- 背景
- 多业务消息通过长连接接入,但消息重要性存在差异
- 如弹幕丢失对用户体验影响小,而邀请 PK 消息丢失会导致 PK 业务流程中断
- 核心设计
- 采用高低优消息通道,重要消息走 “高优通道”,普通消息走 “低优通道”,实现物理隔离,消息分发优先保障重要消息。
- 高优通道保障
- 采用 “双投递” 机制,并在接入层做幂等去重(高优消息为用户级别,数量少,对接入层压力影响小)。
- 双投递的 job 部署在多机房,降低单机房网络抖动的影响。
- 上线效果
- 当遇到内网 / 出网抖动时,内网部署的 job 节点推送异常,但云上高优 job 节点仍能正常推送
- 有效保障高优消息到达,确保高优业务不受影响。
5.5.3 确保消息不丢失
- 背景与目标:
- 消息推送链路涉及服务层到 job、接入层到客户端等多个环节
- 针对整个链路,通过实现必达机制来确保终端的到达率,简称高达功能。
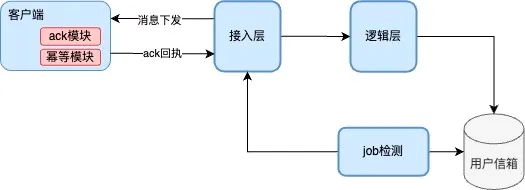
- 功能实现:
- 每条消息引入唯一
msgID,客户端收到消息后,通过幂等模块去重,再通过ack 模块返回接收回执。 - 服务端基于
msgID做 ack 检测,对未收到 ack 的消息,在有效期内重复试下发。
- 每条消息引入唯一